Merencanakan dan melakukan eksperimen untuk menentukan parameter serangan jaringan
Pada tahap pengujian model trafik selanjutnya, perlu diketahui apakah model ini dapat diterapkan pada tugas keamanan jaringan, khususnya untuk mendeteksi serangan jaringan.
Untuk mengetahui rincian intrusi yang tidak sah, diputuskan untuk melakukan eksperimen yang mensimulasikan upaya serangan. Mereka dilakukan di jaringan Samara State Aerospace University (SSAU).
Komputer pribadi jarak jauh yang terhubung ke Internet dan terletak di jaringan eksternal dalam kaitannya dengan jaringan yang diselidiki digunakan sebagai sumber serangan. Target serangan adalah salah satu server internal jaringan SSAU. Router perbatasan jaringan Cisco 6509 SSAU dipilih sebagai sensor NetFlow, kolektor NetFlow adalah server yang sama yang diserang.
Hanya satu komputer yang terlibat dalam pemindaian, karena serangan pemindaian port berasal dari satu sumber. Untuk pemindaian, program Nmap digunakan, yang diinstruksikan untuk melakukan pemindaian penuh semua port server yang diserang.
Nmap adalah utilitas gratis yang dirancang untuk berbagai pemindaian jaringan IP yang dapat disesuaikan dengan sejumlah objek, menentukan status objek dari jaringan yang dipindai (port dan layanan terkait). Nmap menggunakan banyak metode pemindaian yang berbeda seperti UDP, TCP (terhubung), TCP SYN (setengah terbuka), proxy FTP (menerobos ftp), Reverse-ident, ICMP (ping), FIN, ACK, Xmas tree, SYN- dan NULL -pemindaian.
Selama serangan DDoS, target yang diserang adalah server web yang sama seperti pada pemindaian. Beberapa komputer yang berada di jaringan eksternal menjadi sumber serangan. Pada bagian pertama percobaan, menyerang komputer secara bersamaan mengirim permintaan ping selama setengah jam, melakukan serangan banjir ICMP. Pada bagian kedua percobaan, menyerang komputer melakukan serangan DDoS menggunakan program LOIC khusus. Dalam satu jam, server web diserang menggunakan berbagai jenis lalu lintas: HTTP, UDP, TCP. Selama semua percobaan, data dikumpulkan, yang kemudian dianalisis untuk mengidentifikasi pola berbagai jenis serangan.
Gambar 1.16 - Skema percobaan
Aliran data yang menjadi dasar analisis dikumpulkan dari router perbatasan jaringan Cisco 6509. Kolektor nfdump NetFlow digunakan untuk mengumpulkan data dari router. Data NetFlow diekspor untuk analisis setiap lima menit. Setiap lima menit, sebuah file dihasilkan yang menunjukkan parameter semua aliran yang direkam pada router saat ini. Parameter ini tercantum dalam pendahuluan dan meliputi: waktu mulai streaming, durasi streaming, protokol transfer data, alamat sumber dan port, alamat dan port tujuan, jumlah paket yang ditransmisikan, jumlah data yang ditransmisikan dalam byte.
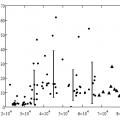
Sebagai hasil dari analisis data yang dikumpulkan selama pemindaian jaringan, peningkatan tajam dalam jumlah aliran aktif terungkap dengan jumlah lalu lintas yang ditransmisikan hampir tidak berubah (lihat Gambar 1.16). Setiap komputer pemindaian menghasilkan sekitar 10-20 ribu aliran yang sangat singkat (berukuran hingga 50 byte) dalam waktu 5 menit. Pada saat yang sama, jumlah total aliran aktif pada router, yang dihasilkan oleh semua pengguna, adalah sekitar 50-60 ribu.
Gambar 1.17 menunjukkan grafik status jaringan, absis mewakili jumlah aliran yang diselesaikan N, dan ordinat mewakili total beban saluran dalam Megabit per detik (Mbps). Setiap titik pada grafik mencerminkan keadaan jaringan yang dipelajari untuk interval lima menit sebelumnya, menunjukkan ketergantungan beban saluran rata-rata pada jumlah aliran aktif. Titik-titik mewakili status jaringan normal, dan segitiga mewakili status jaringan yang ditangkap selama pemindaian port. Batang pada grafik dan sejajar dengan ordinat menunjukkan interval kepercayaan untuk beban rata-rata yang dihitung untuk lima interval aliran (20.000-30.000, 30.000-40.000, 40.000-50.000, 50.000-60.000, 60.000-70000).

Gambar 1.17 - Pemindaian port
Sebagai hasil percobaan dengan permintaan ping, ditemukan bahwa untuk setiap komputer yang menyerang hanya ada satu aliran lalu lintas ICMP yang sangat panjang jika permintaan dikirim pada satu port. Karena data tentang satu aliran ditulis hanya setelah selesai, data yang diperlukan ditulis ke file nfdump setelah serangan berakhir. Satu aliran lalu lintas ICMP yang panjangnya tidak normal terdeteksi dan berasal dari komputer yang menyerang. Jadi, sebagai hasil dari analisis data eksperimen, adalah mungkin untuk mengidentifikasi serangan tipe banjir ICMP. Perlu dicatat bahwa untuk mencapai hasil - kegagalan dalam pengoperasian sistem informasi, satu arus lalu lintas ICMP yang aktif jelas tidak cukup, akun harus masuk ke puluhan ribu permintaan.
Analisis percobaan simulasi serangan DDoS menggunakan utilitas LOIC juga menunjukkan peningkatan tajam dalam jumlah aliran aktif seiring dengan peningkatan lalu lintas yang ditransmisikan. Utilitas secara bersamaan mengirimkan data ke port target yang berbeda, sehingga menciptakan sejumlah besar aliran pendek dengan durasi hingga satu menit (lihat Gambar 1.18). Segitiga mewakili status jaringan yang direkam selama serangan.

Gambar 1.18 - Serangan DDoS
Dengan demikian, menjadi jelas bahwa dengan bantuan protokol NetFlow dimungkinkan untuk mendeteksi tidak hanya saat serangan dimulai, tetapi juga untuk menentukan jenisnya. Penjelasan mendetail tentang algoritme untuk mendeteksi serangan dan cara membuat hosting yang aman dapat ditemukan di bagian berikut.
literatur
1. Bolla R., Bruschi R. RFC 2544 evaluasi kinerja dan pengukuran internal untuk router terbuka berbasis Linux // Peralihan dan Perutean Kinerja Tinggi, 2006 Workshop on. - IEEE, 2006. - S.6 hal.
2. Fraleigh C. dkk. Pengukuran lalu lintas tingkat paket dari tulang punggung IP Sprint // jaringan IEEE. - 2003. - T. 17. - No. 6. - S.6-16.
3. Park K., Kim G., Crovella M. Tentang hubungan antara ukuran file, protokol transport, dan lalu lintas jaringan yang serupa sendiri // Network Protocols, 1996. Proceedings., Konferensi Internasional 1996 pada. - IEEE, 1996 .-- S. 171-180.
4. Fred S.B. dkk. Pembagian bandwidth statistik: studi kemacetan pada tingkat aliran // ACM SIGCOMM Computer Communication Review. - ACM, 2001. - T.31. - No. 4. - S.111-122.
5. Barakat C. dkk. Model berbasis aliran untuk lalu lintas tulang punggung internet // Prosiding Lokakarya SIGCOMM ACM ke-2 tentang pengukuran Internet. - ACM, 2002. - S. 35-47.
6. Sukhov A. M. dkk. Alur aktif dalam diagnostik pemecahan masalah pada tautan tulang punggung // Jurnal Jaringan Berkecepatan Tinggi. - 2011. - T.18. - No. 1. - S.69-81.
7. Pemindaian jaringan Lyon G. F. Nmap: Panduan proyek resmi Nmap untuk penemuan jaringan dan pemindaian keamanan. - Tidak aman, 2009.
8. Haag P. Awasi Alur Anda dengan NfSen dan NFDUMP // Pertemuan RIPE ke-50. - 2005.
Peringkat distribusi untuk menentukan ambang batas untuk variabel jaringan dan menganalisis serangan DDoS
pengantar
Pertumbuhan eksponensial lalu lintas Internet dan jumlah sumber informasi disertai dengan peningkatan pesat dalam jumlah kondisi jaringan yang tidak normal. Keadaan abnormal jaringan dijelaskan oleh alasan buatan manusia dan faktor manusia. Mengenali kondisi anomali yang diciptakan oleh penyusup cukup sulit karena fakta bahwa mereka meniru tindakan pengguna biasa. Oleh karena itu, kondisi abnormal seperti itu sangat sulit untuk diidentifikasi dan diblokir. Tugas memastikan keandalan dan keamanan layanan Internet memerlukan studi tentang perilaku pengguna pada sumber daya tertentu.
Artikel ini akan fokus pada identifikasi kondisi jaringan yang tidak normal dan metode untuk melawan serangan DDoS. (Penolakan Layanan Terdistribusi, serangan penolakan layanan terdistribusi) adalah serangan di mana satu set komputer di Internet, yang disebut "zombie", "bot" atau botnet (botnet), atas perintah penyerang, mulai mengirim permintaan layanan korban. Ketika jumlah permintaan melebihi kapasitas server korban, permintaan baru dari pengguna nyata tidak lagi dilayani dan menjadi tidak tersedia. Dalam hal ini, korban mengalami kerugian finansial.
Studi yang dijelaskan dalam bab tutorial ini menggunakan pendekatan matematika terpadu. Sejumlah variabel jaringan yang paling penting diidentifikasi, yang dihasilkan oleh satu alamat IP eksternal saat mengakses server atau jaringan lokal tertentu. Variabel ini meliputi: frekuensi akses ke server web (pada port tertentu), jumlah aliran aktif, jumlah lalu lintas TCP, UDP, dan ICMP yang masuk, dll. Infrastruktur yang dibangun memungkinkan untuk mengukur nilai untuk variabel jaringan di atas.
Setelah menemukan nilai-nilai ini untuk variabel yang dianalisis pada waktu yang berubah-ubah, perlu untuk membangun distribusi peringkat. Untuk ini, nilai yang ditemukan diatur dalam urutan menurun. Analisis status jaringan akan dilakukan dengan membandingkan distribusi yang sesuai. Perbandingan ini sangat jelas ketika distribusi untuk status jaringan abnormal dan normal diplot pada grafik yang sama. Pendekatan ini memudahkan untuk menentukan batas antara kondisi jaringan normal dan tidak normal.
Eksperimen pada serangan DDoS pada layanan dapat dilakukan menggunakan emulasi di lingkungan lab. Pada saat yang sama, nilai hasil yang diperoleh secara signifikan lebih kecil daripada dalam kasus serangan DDoS pada layanan komersial yang dioperasikan, karena emulator tidak dapat sepenuhnya mereproduksi jaringan komputer nyata. Selain itu, pengalaman dengan serangan DDoS diperlukan untuk memahami sepenuhnya prinsip dan metode serangan DDoS. Oleh karena itu, penulis secara anonim setuju untuk melakukan serangan DDoS nyata pada layanan web yang disiapkan secara khusus. Selama serangan, lalu lintas jaringan dicatat dan statistik NetFlow dikumpulkan. Mempelajari distribusi peringkat untuk jumlah aliran dan berbagai jenis lalu lintas masuk yang dihasilkan oleh satu alamat IP eksternal, yang memungkinkan untuk menentukan nilai ambang batas. Melebihi nilai ambang batas dapat diklasifikasikan sebagai tanda node yang menyerang, yang memungkinkan ditarik kesimpulan tentang efektivitas metode deteksi dan tindakan pencegahan.
Hal pertama yang menarik perhatian di ranah dokumen adalah pertumbuhan penduduknya yang sangat pesat.
Fakta yang terkenal ini membuat seseorang berpikir serius tentang apa yang dapat menyebabkan pertumbuhan seperti itu. Tapi mungkin ketakutan kita sia-sia, dan di masa depan laju peningkatan jumlah dokumen akan melambat? Sejauh ini, statistik mengkonfirmasi sebaliknya.
Beginilah, misalnya, aliran informasi dokumenter tentang kimia telah berubah. Pada tahun 1732, seluruh warisan ilmu kimia dirangkum dan diterbitkan oleh seorang profesor Belanda dalam sebuah buku setebal 1433 halaman. Pada tahun 1825, ilmuwan Swedia Berzelius menerbitkan semua yang diketahui dalam kimia dalam 8 volume, dengan total 4.150 halaman. Saat ini, jurnal abstrak Amerika "Chemical Abstracts", yang diterbitkan sejak 1907, menerbitkan hampir semua informasi tentang kimia, sedangkan satu juta abstrak pertama diterbitkan 31 tahun kemudian, yang kedua - setelah 18 tahun, yang ketiga - setelah 7 tahun, dan yang kedua - setelah 18 tahun, yang ketiga - setelah 7 tahun. keempat - dalam 4 tahun!
Pola pertumbuhan jumlah dokumen yang kurang lebih sama dapat ditelusuri di bidang ilmu pengetahuan lainnya. Telah diamati bahwa pertumbuhan dokumen adalah eksponensial. Pada saat yang sama, peningkatan tahunan arus informasi ilmiah dan teknis adalah 7 ... 10%. Saat ini, setiap 10 ... 15 tahun terjadi dua kali lipat volume informasi ilmiah dan teknis (IMS) Kurva pertumbuhan jumlah dokumen, dengan demikian, dapat digambarkan dengan eksponen bentuk
kamu = ae kt
di mana kamu- jumlah pengetahuan yang diwarisi dari generasi sebelumnya, e Apakah basis logaritma natural ( e = 2,718...), T- indeks waktu (g); SEBUAH- jumlah pengetahuan pada asalnya (untuk T = 0), K- koefisien yang mencirikan kecepatan pengetahuan, yang setara dengan aliran informasi ilmiah dan teknis. Pada T 10 ... 15 tahun pada = 2SEBUAH.
Sangat mudah untuk membayangkan bahwa pertumbuhan jumlah dokumen ilmiah seperti itu bukanlah pertanda baik bagi kita di masa depan, bahkan dalam waktu dekat. Hutan berubah menjadi pegunungan kertas di mana seorang penjelajah tak berdaya tenggelam ...
Namun, sebagaimana ditunjukkan oleh sejarah ilmu pengetahuan dan teknologi, kondisi di mana mereka berkembang tidak konstan, sehingga mekanisme pertumbuhan eksponensial aliran IMS sering dilanggar. Pelanggaran ini dijelaskan oleh sejumlah faktor penghambat, khususnya perang, kekurangan material dan sumber daya manusia, dll. Kenyataannya, pertumbuhan jumlah dokumen karena itu tidak mematuhi ketergantungan eksponensial, meskipun pada periode tertentu perkembangan ilmu pengetahuan dan teknologi di bidang pengetahuan tertentu, itu memanifestasikan dirinya dengan cukup jelas. Apa alasan peningkatan pesat arus informasi dokumenter?
Pada bagian sebelumnya, kami menarik perhatian pada fakta bahwa informasi memainkan peran besar dalam perkembangan masyarakat manusia, oleh karena itu disertai dengan pertumbuhan volume informasi yang luar biasa. Pertumbuhan aliran dokumenter informasi ilmiah dapat dikaitkan dengan peningkatan jumlah pencipta informasi ilmiah. Tingkat pertumbuhan ini dijelaskan oleh fungsi eksponensial. Misalnya, selama 50 tahun terakhir, jumlah pekerja ilmiah di Uni Soviet telah berlipat ganda setiap 7 tahun, di AS - setiap 10 tahun, di negara-negara Eropa - setiap 10 ... 15 tahun.
Tentu saja, laju pertumbuhan jumlah pekerja ilmiah harus melambat dan mencapai nilai yang kurang lebih konstan dalam kaitannya dengan seluruh jumlah populasi pekerja. Jika tidak, seluruh populasi setelah beberapa waktu akan terlibat dalam pekerjaan penelitian dan pengembangan, yang tidak realistis. Oleh karena itu, di masa depan, kita harus mengharapkan perlambatan laju pertumbuhan jumlah dokumen ilmiah. Saat ini, tarif ini masih tinggi dan mengilhami konsumen informasi dengan kecemasan: bagaimana cara menyimpan dan memproses dokumen, bagaimana menemukan yang tepat di antara mereka?
Situasinya tampak tanpa harapan: hukum pertumbuhan eksponensial dokumen, yang masih berlaku di kerajaan dokumen, telah secara tajam memperburuk masalah "perumahan" dan "transportasi" di dalamnya.
Namun, ternyata, ada undang-undang di sini yang agak meringankan situasi saat ini ...
Pada akhir 40-an abad kita, J. Zipf, setelah mengumpulkan bahan statistik yang sangat besar, mencoba menunjukkan bahwa distribusi kata-kata dalam bahasa alami mematuhi satu hukum sederhana, yang dapat dirumuskan sebagai berikut. Jika Anda menyusun daftar semua kata yang muncul di dalamnya untuk beberapa teks yang cukup besar, maka urutkan kata-kata ini dalam urutan menurun frekuensi kemunculannya dalam teks ini dan beri nomor dalam urutan dari 1 (nomor urut kata yang paling sering) ke R, maka untuk setiap kata produk dari nomor urutnya (peringkat) / dalam daftar tersebut dan frekuensi kemunculannya dalam teks akan menjadi nilai konstanta yang memiliki arti yang kurang lebih sama untuk kata apa pun dari daftar ini. Secara analitis, hukum Zipf dapat dinyatakan sebagai
dari = C,
di mana F- frekuensi kemunculan kata dalam teks;
R- peringkat (nomor urut) kata dalam daftar;
Dengan Adalah konstanta empiris.
Ketergantungan yang dihasilkan secara grafis dinyatakan dengan hiperbola. Setelah mempelajari berbagai teks dan bahasa,
termasuk bahasa seribu tahun yang lalu, J. Zipf membangun ketergantungan yang ditunjukkan untuk masing-masingnya, sementara semua kurva memiliki bentuk yang sama - bentuk "tangga hiperbolik", mis. mengganti satu teks dengan yang lain tidak mengubah karakter umum distribusi.
Hukum Zipf ditemukan secara eksperimental. Kemudian B. Mandelbrot menawarkan landasan teoretisnya. Dia percaya bahwa seseorang dapat membandingkan bahasa tertulis dengan pengkodean, dan semua tanda harus memiliki "nilai" tertentu. Berangkat dari persyaratan biaya pesan minimum, B. Mandelbrot secara matematis mencapai ketergantungan yang mirip dengan hukum Zipf
dari γ = C ,
di mana adalah nilai (mendekati satu), yang dapat bervariasi tergantung pada properti teks.
J. Zipf dan peneliti lain menemukan bahwa tidak hanya semua bahasa alami di dunia yang mematuhi distribusi ini, tetapi juga fenomena lain yang bersifat sosial dan biologis: distribusi ilmuwan dengan jumlah artikel yang diterbitkan oleh mereka (A. Lotka, 1926), kota-kota AS menurut jumlah penduduk (J. Zipf, 1949), penduduk menurut pendapatan di negara-negara kapitalis (V. Pareto, 1897), genera biologis menurut jumlah spesies (J. Willis, 1922), dll.
Hal terpenting untuk masalah yang kami pertimbangkan adalah fakta bahwa dokumen dalam cabang ilmu apa pun dapat didistribusikan menurut undang-undang ini. Kasus khusus adalah hukum Bradford, yang tidak lagi terkait langsung dengan distribusi kata-kata dalam teks, tetapi dengan distribusi dokumen dalam area tematik.
Ahli kimia dan bibliografi Inggris S. Bradford, mempelajari artikel tentang geofisika terapan dan pelumasan, memperhatikan bahwa distribusi jurnal ilmiah yang berisi artikel tentang pelumasan dan jurnal yang berisi artikel tentang geofisika terapan memiliki bentuk umum. Berdasarkan fakta yang ada, S. Bradford merumuskan pola distribusi publikasi berdasarkan edisi.
Arti utama dari pola tersebut adalah sebagai berikut: jika jurnal ilmiah disusun dalam urutan jumlah artikel pada masalah tertentu, maka jurnal dalam daftar yang dihasilkan dapat dibagi menjadi tiga zona sehingga jumlah artikel di setiap zona pada subjek tertentu adalah sama. Pada saat yang sama, zona pertama, yang disebut zona inti, mencakup jurnal khusus yang secara langsung ditujukan untuk topik yang sedang dibahas. Jumlah jurnal khusus di zona inti kecil. Zona kedua dibentuk oleh jurnal, sebagian dikhususkan untuk area tertentu, dan jumlahnya meningkat secara signifikan dibandingkan dengan jumlah jurnal di inti. Zona ketiga, terbesar dalam hal jumlah publikasi, menyatukan jurnal yang topiknya sangat jauh dari topik yang dibahas.
Dengan demikian, dengan jumlah publikasi yang sama pada topik tertentu di setiap zona, jumlah judul jurnal meningkat tajam ketika berpindah dari satu zona ke zona lainnya. S. Bradford menemukan bahwa jumlah majalah di zona ketiga kira-kira sebanyak di zona kedua, berapa kali jumlah judul di zona kedua lebih banyak daripada di zona pertama. Kami menunjukkan R 1 - jumlah majalah di zona 1, R 2 - di tanggal 2, R 3 - jumlah majalah di zona ke-3.
Jika sebuah- perbandingan jumlah jurnal di zona 2 dengan jumlah jurnal di zona 1, maka pola yang diungkapkan oleh S. Bradford dapat ditulis sebagai berikut:
P 1: P 2: P 3 = 1: sebuah : sebuah 2
P 3: P 2 = P 2: P 1 = sebuah.
Ketergantungan ini disebut hukum Bradford.
B. Vickery menyempurnakan model S. Bradford. Dia menemukan bahwa jurnal-jurnal, yang diberi peringkat (berbaris) dalam urutan menurun artikel mereka tentang masalah tertentu, tidak dapat dibagi menjadi tiga zona, tetapi menjadi beberapa zona yang diperlukan. Jika terbitan berkala disusun dalam urutan pengurangan jumlah artikel tentang masalah tertentu, maka dalam daftar yang dihasilkan, sejumlah zona dapat dibedakan, yang masing-masing berisi jumlah artikel yang sama. Kami mengambil notasi berikut: x- jumlah artikel di setiap zona. Tx- jumlah majalah yang memuat x artikel, T 2x- jumlah majalah yang berisi 2 x artikel, yaitu jumlah judul majalah di zona 1 dan 2, T 3x- jumlah majalah yang berisi 3 x artikel, yaitu jumlah judul majalah di zona 1, 2 dan 3, T 4x- jumlah majalah yang berisi 4 x artikel.
Maka pola ini akan memiliki bentuk
Tx : T 2x : T 3x : T 4x : ... = 1: sebuah : sebuah 2: sebuah 3: ...
Ungkapan ini disebut hukum Bradford dalam interpretasi B. Vickery.
Jika hukum Zipf mencirikan banyak fenomena yang bersifat sosial dan biologis, maka hukum Bradford adalah kasus khusus distribusi Zipf untuk sistem majalah sains dan teknologi.
Dari pola-pola ini orang dapat menarik kesimpulan yang sangat bernilai praktis.
Jadi, jika Anda menyusun majalah apa pun dalam urutan menurun dari jumlah artikel pada profil tertentu, maka, menurut Bradford, mereka dapat dibagi menjadi tiga kelompok yang berisi jumlah artikel yang sama. Misalkan kita memilih sekelompok 8 judul majalah yang menempati 8 tempat pertama dalam daftar yang dihasilkan. Kemudian, untuk menggandakan jumlah artikel di profil yang menarik bagi kami, kami harus menambahkan 8 lagi ke 8 yang ada sebuah judul majalah. Jika sebuah= 5 (nilai ini ditemukan secara eksperimental untuk beberapa bidang tematik), maka jumlah judul ini adalah 40. Maka jumlah total judul majalah adalah 48, yang tentu saja lebih dari 8. Ketika mencoba untuk mendapatkan tiga kali lebih banyak artikel, kita harus meliput 8 + 5 8 + 5 2 8 = 256 judul! Dari jumlah tersebut, sepertiga dari artikel yang menarik bagi kami terkonsentrasi hanya di 8 jurnal, yaitu. artikel didistribusikan secara tidak merata di antara nama-nama jurnal. Di satu sisi, ada konsentrasi sejumlah besar artikel tentang topik tertentu di beberapa jurnal khusus, di sisi lain, ada hamburan artikel ini di sejumlah besar publikasi terkait atau jauh dari topik yang sedang dibahas. pertimbangan, sementara dalam praktiknya perlu untuk mengidentifikasi sumber utama untuk bidang yang kami minati, pengetahuan teknis, bukan edisi acak.
Pola pemusatan dan penyebaran informasi ilmiah dan teknis di bidang dokumen memungkinkan untuk memilih secara tepat publikasi yang paling mungkin memuat publikasi yang sesuai dengan profil pengetahuan tertentu. Dalam proses masifnya dukungan informasi dalam skala nasional, penggunaan pola-pola tersebut memungkinkan kita untuk menekan biaya yang sangat besar bagi perekonomian nasional.
Penyebaran publikasi yang ada tidak dapat dinilai hanya sebagai berbahaya. Dalam lingkungan yang tersebar, peluang untuk pertukaran informasi lintas sektoral ditingkatkan.
Upaya untuk memusatkan semua publikasi satu profil di beberapa jurnal, mis. untuk mencegah penyebarannya, akan memiliki konsekuensi negatif, belum lagi fakta bahwa penugasan dokumen yang tepat ke profil tertentu tidak selalu memungkinkan.
Hasil pengujian hukum hamburan Bradford, seperti yang ditunjukkan oleh S. Brooks, memiliki derajat kesepakatan yang berbeda. Terlepas dari amandemen yang dibuat, model Bradford tidak mencerminkan keragaman distribusi nyata. Perbedaan ini dapat dijelaskan oleh fakta bahwa Bradford membuat kesimpulannya berdasarkan pilihan array yang hanya terkait dengan area tematik yang sempit.
Kelebihan besar J. Zipf dan S. Bradford adalah bahwa mereka meletakkan dasar untuk studi ketat arus informasi dokumenter (DIP), yang merupakan kumpulan publikasi ilmiah dan materi yang tidak dipublikasikan (misalnya, laporan tentang pekerjaan penelitian dan pengembangan ). Penelitian lebih lanjut, di antaranya tempat yang menonjol ditempati oleh karya spesialis Soviet di bidang informatika V.I. Gorkova, menunjukkan bahwa dimungkinkan untuk menentukan tidak hanya parameter kuantitatif set dokumen ilmiah, tetapi juga set elemen tanda dokumen ilmiah: penulis, istilah, indeks sistem klasifikasi, judul publikasi, mis. nama-nama unsur yang mencirikan isi dokumen ilmiah. Misalnya, Anda dapat mengatur jurnal dalam urutan menurun dari jumlah penulis yang diterbitkan di dalamnya, dalam urutan menurun dari jumlah rata-rata artikel yang diterbitkan di dalamnya, atau mengatur kumpulan dokumen dengan salah satu elemennya.
Urutannya ditentukan oleh peringkat (urutan penempatan) nama-nama elemen menurut frekuensi kemunculannya dalam urutan menurun. Kumpulan nama item yang berurutan ini disebut distribusi peringkat. Distribusi yang dipelajari Zipf pada saat itu adalah contoh khas dari distribusi peringkat. Ternyata jenis distribusi peringkat, strukturnya mencirikan kumpulan dokumen yang menjadi milik distribusi peringkat yang diberikan. Ternyata, ketika membangun, distribusi peringkat dalam banyak kasus memiliki bentuk keteraturan Zipf dengan koreksi Mandelbrot:
dari γ = C.
Dalam hal ini, koefisien adalah besaran variabel. Keteguhan koefisien tetap hanya di bagian tengah grafik distribusi. Bagian ini berbentuk garis lurus, jika grafik keteraturan di atas diplot dalam koordinat logaritma. Bagian distribusi dengan = konstan disebut zona pusat dari distribusi peringkat (nilai argumen di bagian ini bervariasi dari inr 1, sebelumnya inr 2). Nilai argumen dari 0 hingga inr 1 sesuai dengan zona kernel distribusi peringkat, dan nilai argumen dari inr 2 sampai inr 3 - yang disebut zona pemotongan.
Apa arti dari keberadaan tiga zona distribusi pangkat yang dapat dibedakan dengan jelas? Jika yang terakhir mengacu pada istilah yang membentuk bidang pengetahuan apa pun, maka zona nuklir, atau zona inti distribusi peringkat, berisi istilah ilmiah umum yang paling umum digunakan. Zona tengah berisi istilah yang paling khas untuk bidang pengetahuan tertentu, yang bersama-sama mengekspresikan kekhususannya, berbeda dengan ilmu lain, "mencakup konten utamanya." Zona pemotongan berisi istilah yang relatif jarang digunakan di bidang pengetahuan ini.
Dengan demikian, dasar kosa kata dari setiap bidang pengetahuan terkonsentrasi di zona tengah distribusi peringkat. Dengan bantuan istilah zona nuklir, bidang pengetahuan ini "bergabung dengan bidang pengetahuan yang lebih umum," dan zona pemotongan memainkan peran garda depan, seolah-olah "meraba-raba" untuk koneksi dengan cabang ilmu lain. . Jadi, jika beberapa tahun yang lalu istilah "laser" akan ditemukan dalam distribusi peringkat istilah di area tematik "Pemrosesan logam", maka, karena kemunculannya yang rendah, mungkin akan jatuh ke zona pemotongan: hubungan antara teknologi laser dan pemrosesan logam masih hanya "terasa". Namun, hari ini istilah ini tidak diragukan lagi akan jatuh ke zona tengah, yang akan mencerminkan kemunculannya yang agak tinggi dan, oleh karena itu, koneksi yang stabil antara teknologi laser dan pemrosesan logam.
Grafik distribusi peringkat dipenuhi dengan makna yang dalam: lagi pula, dengan ukuran relatif dari zona tertentu pada grafik, seseorang dapat menilai karakteristik seluruh bidang pengetahuan. Grafik dengan zona nuklir besar dan zona pemotongan kecil termasuk dalam bidang pengetahuan yang cukup luas dan kemungkinan besar konservatif. Untuk cabang sains yang dinamis, zona pemotongan yang meningkat adalah karakteristik. Ukuran kecil dari zona nuklir dapat menunjukkan orisinalitas bidang pengetahuan yang menjadi milik distribusi peringkat yang dibangun, dll. Jadi, berdasarkan analisis distribusi peringkat, ternyata dimungkinkan untuk memberikan penilaian kualitatif arus informasi dokumenter sesuai dengan cabang ilmu di mana mereka terbentuk. Kerajaan dokumen mengambil garis besar sistem di mana elemen-elemennya saling berhubungan, dan hukum yang mengatur hubungan ini dapat dipelajari!
Ketika informasi semakin tua ...
Penuaan ... Arti konsep ini tidak memerlukan penjelasan, itu sudah diketahui semua orang. Planet kita menua, pohon menua. Hal-hal dan orang-orang yang menjadi miliknya semakin menua. Dokumen juga semakin tua. Lembar buku menguning, huruf memudar, sampul runtuh. Tapi apa itu? Seorang siswa, menyingkirkan buku yang ditawarkan kepadanya di perpustakaan, dengan acuh tak acuh berkomentar: "Ini sudah ketinggalan zaman!", Meskipun buku itu terlihat benar-benar baru! Tentu saja, tidak ada rahasia di sini. Buku ini baru, tetapi informasi yang dikandungnya mungkin sudah ketinggalan zaman. Berkenaan dengan dokumen, penuaan dipahami bukan sebagai penuaan fisik pembawa informasi, tetapi sebagai proses penuaan yang agak kompleks dari informasi yang dikandungnya. Secara lahiriah, proses ini memanifestasikan dirinya dalam hilangnya minat para ilmuwan dan spesialis dalam publikasi dengan peningkatan waktu yang telah berlalu sejak hari publikasi mereka. Seperti yang ditunjukkan oleh survei terhadap 17 perpustakaan, yang dilakukan oleh salah satu badan informasi sektoral, 62% dari permintaan adalah untuk jurnal yang berusia kurang dari 1,5 tahun; 31% dari permintaan - ke majalah 1,5 ... 5 tahun; 6% - untuk majalah berusia 6 hingga 10 tahun; 7% - untuk majalah berusia di atas 10 tahun. Publikasi yang telah diterbitkan untuk waktu yang relatif lama lebih jarang dirujuk, yang menimbulkan pernyataan penuaan mereka. Apa mekanisme yang mengatur proses penuaan dokumen?
Salah satunya terkait langsung dengan akumulasi, agregasi informasi ilmiah. Seringkali materi yang seratus tahun yang lalu membutuhkan seluruh mata kuliah untuk dijelaskan sekarang dapat dijelaskan dalam hitungan menit dengan menggunakan dua atau tiga rumus. Kursus kuliah yang sesuai semakin menua: tidak ada yang menggunakannya lagi.
Setelah menerima data perkiraan yang lebih akurat, dan karenanya dokumen-dokumen di mana mereka diterbitkan, usia. Oleh karena itu, ketika mereka berbicara tentang penuaan informasi ilmiah, yang paling sering mereka maksud adalah penyempurnaannya, presentasi yang lebih ketat, ringkas dan umum dalam proses pembuatan informasi ilmiah baru. Ini dimungkinkan karena fakta bahwa informasi ilmiah memiliki sifat kumulatif, mis. memungkinkan untuk presentasi yang lebih ringkas dan umum.
Terkadang penuaan informasi dokumenter memiliki mekanisme yang berbeda: objek, deskripsi yang kita miliki, berubah dari waktu ke waktu sedemikian rupa sehingga informasi tentangnya menjadi tidak akurat. Beginilah cara peta geografis menua: padang rumput menggantikan gurun, kota dan laut baru muncul.
Proses penuaan juga dapat dilihat sebagai hilangnya informasi praktis bagi konsumen. Artinya dia tidak bisa lagi menggunakannya untuk mencapai tujuannya.
Dan, akhirnya, proses ini dapat dipertimbangkan dari sudut pandang mengubah tesaurus manusia. Dari sudut pandang ini, informasi yang sama mungkin “ketinggalan zaman” untuk satu orang dan “ketinggalan zaman” untuk orang lain.
Tingkat penuaan informasi dokumenter tidak sama untuk berbagai jenis dokumen. Tingkat penuaan dipengaruhi oleh berbagai tingkat oleh banyak faktor. Keunikan penuaan informasi di setiap bidang ilmu pengetahuan dan teknologi tidak dapat diturunkan atas dasar pertimbangan abstrak atau data statistik rata-rata - mereka secara organik terkait dengan tren perkembangan masing-masing cabang ilmu pengetahuan dan teknologi yang terpisah.
Untuk mengukur tingkat penuaan informasi, pustakawan R. Barton dan fisikawan R. Kebler dari AS, dengan analogi dengan waktu paruh zat radioaktif, memperkenalkan "waktu paruh" artikel ilmiah. Waktu paruh adalah waktu di mana setengah dari semua literatur yang digunakan saat ini tentang industri atau subjek tertentu telah diterbitkan. Jika waktu paruh publikasi dalam fisika adalah 4,6 tahun, ini berarti bahwa 50% dari semua publikasi yang saat ini digunakan (dikutip) dalam bidang ini tidak lebih dari 4,6 tahun. Berikut adalah hasil yang diperoleh Barton dan Kebler: untuk publikasi dalam fisika - 4,6 tahun, fisiologi - 7,2, kimia - 8.1, botani - 10,0, matematika - 10.5, geologi - 11,8 tahun. Namun, meskipun properti penuaan informasi bersifat objektif, itu tidak mengungkapkan proses internal pengembangan bidang pengetahuan ini dan agak deskriptif. Oleh karena itu, kesimpulan tentang penuaan informasi harus diperlakukan dengan sangat hati-hati.
Namun demikian, bahkan perkiraan perkiraan tingkat penuaan informasi dan dokumen yang berisi itu adalah nilai praktis yang besar: membantu untuk tetap terlihat hanya bagian dari kerajaan dokumen, yang, kemungkinan besar, berisi dokumen yang membawa informasi dasar tentang suatu ilmu yang diberikan. Hal ini penting tidak hanya bagi pegawai perpustakaan ilmiah dan teknis serta badan informasi ilmiah dan teknis, tetapi juga bagi konsumen IMS itu sendiri.
Keluar dalam otomatisasi?
ANALISIS PERINGKAT SEBAGAI METODE PENELITIAN
Universitas Negeri Ulyanovsk
Salah satu hukum paling umum tentang perkembangan sistem biologis, teknis, sosial adalah hukum distribusi pangkat. Teori analisis peringkat ((RA) dipindahkan dari biologi dan dikembangkan untuk teknologi lebih dari 30 tahun yang lalu oleh seorang profesor di MPEI dan sekolahnya ( www kudrinbi. ru). Ternyata kemudian, metode ini berlaku untuk fisik dan astronomis, dan sistem sosial. Metode untuk membangun distribusi peringkat dan penggunaan selanjutnya untuk tujuan pengoptimalan cenosis buat arti utama analisis peringkat (pendekatan cenologis), konten dan teknologi yang, pada kenyataannya, merupakan arah baru, menjanjikan hasil praktis yang luar biasa. Tujuan dari pekerjaan ini adalah untuk menggambarkan metode analisis peringkat. Baru adalah penyertaan dalam RA dari "metode pelurusan" yang dikenal dalam penelitian fisik, grafik eksperimental yang diperoleh peneliti (konstruksi dan pelurusan dalam koordinat yang sesuai) untuk menentukan jenis ketergantungan matematisnya dan menghitung parameter spesifiknya.
1. Perangkat konseptual teori cenologi. Hukum distribusi peringkat.
koenosis sebut populasi besar individu .
Jumlah individu dalam cenosis menentukan kekuatan populasi. Terminologi ini berasal dari biologi, dari teori biocenosis. "Biocenosis" adalah sebuah komunitas. Ketentuan biocenosis, diperkenalkan oleh Möbius (1877), membentuk dasar ekologi sebagai ilmu. Profesor MPEI mentransfer konsep "cenosis", "individu", "populasi", "spesies" dan dari biologi ke teknologi: dalam teknik "individu" - produk teknis individu, parameter teknis, dan serangkaian besar produk teknis ( individu) disebut teknocenosis... mendefinisikan spesimen teknis sebagai elemen realitas teknis yang terpisah dan tidak dapat dibagi lagi, yang memiliki karakteristik dan fungsi individu dalam siklus hidup individu. Melihat- unit struktural utama dalam taksonomi individu. Spesies adalah sekelompok individu dengan karakteristik kualitatif dan kuantitatif yang mencerminkan esensi dari kelompok ini. Jenis teknologi disebut merek atau model teknologi dan dibuat sesuai dengan satu desain dan dokumentasi teknologi (traktor "Belarus", sekop pencari ranjau, kendaraan ZIL-131, dll.).
Di bidang sosial, "individu" adalah orang, kelompok sosial yang terorganisir (kelas, kelompok belajar) serta sistem sosial (lembaga), misalnya, pendidikan - sekolah. Kemudian dengan analogi, sosiocenosis kita akan menyebut kumpulan individu sosial apa pun. Setiap individu adalah unit struktural cenosis. Seorang individu dapat berupa unit apa pun dari lingkungan sosial, itu tergantung pada skala asosiasi dan pada apa yang digabungkan menjadi cenosis. Misalnya kelas, kelompok belajar adalah sociocenosis yang terdiri dari individu – siswa. Maka pangkat dari populasi adalah banyaknya siswa dalam kelas tersebut. Sekolah juga merupakan sosiocenosis, yang terdiri dari individu - unit struktural terpisah - kelas. Di sini, daya tampung penduduk adalah jumlah kelas di sekolah tersebut. Satu set sekolah adalah cenosis dari skala yang lebih besar, di mana sekolah adalah individu, unit struktural dari cenosis yang diberikan.
Dalam sistematika lembaga pendidikan menengah, berikut ini dapat dibedakan: jenis: sekolah menengah, bacaan, gimnasium, sekolah swasta. Jenis-jenis ini berbeda dalam isi program, tugas, dan cenosis spesies dimana setiap spesies sudah menjadi individu.
Di bawah distribusi peringkat distribusi yang diperoleh sebagai hasil dari prosedur peringkat untuk urutan nilai parameter yang ditetapkan ke peringkat dipahami. Pemeringkatan adalah prosedur untuk mengurutkan objek menurut tingkat keparahan kualitas tertentu. Seorang individu adalah objek peringkat. Pangkat - itu adalah jumlah individu dalam urutan dalam distribusi tertentu. Po, hukum distribusi peringkat individu dalam teknocenosis (distribusi-H ) memiliki bentuk hiperbola:
Dimana W adalah parameter peringkat individu; r - nomor rangking individu (1,2,3….); A adalah nilai maksimum parameter individu terbaik dengan pangkat r = 1, yaitu pada titik pertama (atau koefisien aproksimasi); adalah koefisien peringkat yang mencirikan derajat kecuraman kurva distribusi (keadaan terbaik teknocenosis, misalnya, adalah keadaan di mana parameter berada dalam 0,5 < β < 1,5).
Jika ada parameter cenosis (sistem) yang diberi peringkat, maka distribusinya disebut peringkat parametrik.
Parameter peringkat dalam technocenosis adalah spesifikasi teknis(jumlah fisik atau teknis) yang mencirikan seseorang, misalnya, ukuran, massa, konsumsi daya, energi radiasi, dll. Dalam sosiocenosis, khususnya cenosis pedagogis, parameter peringkat dapat berupa kinerja akademik, peringkat dalam poin peserta dalam olimpiade atau pengujian ; jumlah siswa yang terdaftar di universitas dan sebagainya, dan individu yang diperingkat adalah siswa itu sendiri, kelas, kelompok belajar, sekolah, dan sebagainya.
Jika kekuatan populasi (jumlah individu yang merupakan spesies dalam sosiocenosis) dianggap sebagai parameter, maka dalam hal ini distribusinya disebut peringkat tertentu. Dengan demikian, spesies diurutkan dalam distribusi spesies berperingkat. Artinya, spesies adalah individu.
2. Metodologi untuk menerapkan analisis peringkat
Analisis peringkat mencakup langkah-langkah prosedur berikut:
1. Isolasi cenosis.
2. Mengatur parameter pembentuk spesies. Parameter pembentuk spesies peralatan dapat berupa biaya, keandalan energi, jumlah personel pemeliharaan, berat dan dimensi, dll.
3. Deskripsi parametrik dari cenosis. Berkontribusi untuk basis data nilai parameter spesifik cenosis. Pekerjaan statistik ini sangat dipermudah dengan penggunaan komputer. Pekerjaan membuat basis informasi cenosis selesai setelah tabel elektronik (database) dibuat, yang mencakup informasi sistematis tentang nilai-nilai parameter pembentuk spesies individu individu yang termasuk dalam sociocenosis.
4. Konstruksi distribusi peringkat yang ditabulasi Distribusi peringkat yang ditabulasikan dalam bentuk tabel dua kolom: parameter individu W disusun berdasarkan peringkat dan nomor peringkat individu r (parametrik atau spesifik).
Peringkat pertama diberikan kepada individu dengan nilai parameter maksimum, yang kedua - untuk individu dengan nilai parameter tertinggi di antara individu, kecuali yang pertama, dan seterusnya.
5. Konstruksi distribusi parametrik peringkat grafis atau distribusi spesies peringkat grafis. Kurva peringkat parametrik memiliki bentuk hiperbola, dengan nomor peringkat r diplot pada sumbu absis, dan parameter yang dipelajari W pada sumbu ordinat Grafik distribusi spesies peringkat adalah sekumpulan titik: setiap titik grafik bersesuaian untuk individu tertentu atau jenis cenosis. Dalam hal ini, absis pada grafik adalah peringkat, dan ordinat adalah parameter individu (distribusi parametrik) atau jumlah individu yang diwakili spesies ini dalam cenosis (distribusi spesies peringkat). Semua data diambil dari distribusi tabel.
6. Perkiraan distribusi. Inti dari metode ini adalah untuk menemukan parameter ketergantungan analitik yang meminimalkan jumlah kuadrat dari deviasi nilai empiris y yang sebenarnya diperoleh selama analisis peringkat sosiocenosis dari nilai yang dihitung dari aproksimasi ketergantungan. Perlu dicatat bahwa perkiraan dan parameter ekspresi dapat ditentukan dengan menggunakan program komputer. Parameter kurva distribusi ditemukan: A, b. Sebagai aturan, untuk technocenosis 0,5. < β < 1,5.
7. Optimalisasi cenosis.
Optimasi adalah salah satu operasi yang paling sulit dari teori coenological. Sejumlah besar karya dikhususkan untuk bidang penelitian ini. Prosedur optimasi sistem (cenosis) terdiri dari membandingkan kurva ideal dengan kurva nyata, setelah itu ditarik kesimpulan: apa yang secara praktis perlu dilakukan dalam cenosis agar titik-titik kurva nyata cenderung terletak pada ideal melengkung. Mari kita pertimbangkan beberapa prosedur pengoptimalan paling sederhana untuk cenosis, yang telah kami uji secara ekstensif dalam praktik. Mari kita lihat lebih dekat pada tahap 7.
Sebagai aturan, distribusi H nyata berbeda dari yang ideal dengan penyimpangan berikut:
1) beberapa titik percobaan berada di luar distribusi ideal;
2) grafik percobaan bukan hiperbola;
3) kurva eksperimental, secara keseluruhan, memiliki karakter distribusi-H, tetapi dibandingkan dengan yang teoritis, ia memiliki "punuk", "palung" atau "ekor".
4) hiperbola nyata terletak di bawah hiperbola ideal, atau sebaliknya, hiperbola nyata terletak di atas hiperbola ideal.
Prosedur optimasi untuk setiap cenosis (penentuan metode, sarana dan kriteria untuk perbaikannya) ditujukan untuk menghilangkan penyimpangan abnormal dalam distribusi peringkat. Setelah mengidentifikasi anomali pada distribusi grafis, menurut distribusi yang ditabulasi, individu yang "bertanggung jawab" untuk anomali ditentukan, dan langkah-langkah prioritas untuk eliminasinya diuraikan.
Optimasi cenosis dilakukan dengan dua cara:
1. Optimalisasi nomenklatur - perubahan yang disengaja dalam jumlah cenosis (nomenklatur), mengarahkan distribusi spesies cenosis dalam bentuk ke kanonik (teladan, ideal). Dalam biocenosis - kawanan adalah pengusiran atau penghancuran individu yang lemah, dalam kelompok studi - penghapusan yang tidak berhasil.
2. Optimalisasi parametrik - perubahan (peningkatan) yang disengaja dari parameter individu individu, mengarahkan cenosis ke keadaan yang lebih stabil dan, karenanya, efektif. Dalam cenosis pedagogis - kelompok belajar (kelas) - ini bekerja dengan yang tidak berhasil - meningkatkan parameter individu.
Semakin dekat kurva distribusi eksperimental mendekati kurva ideal bentuk (1), semakin stabil sistem tersebut. Setiap penyimpangan menunjukkan bahwa baik nomenklatur atau optimasi parametrik diperlukan. Penyimpangan dari distribusi-H ideal (hiperbola) disajikan dalam bentuk titik-titik yang keluar dari grafik, "ekor" dari "punuk", "lembah", serta degenerasi hiperbola menjadi garis lurus atau grafik lainnya. dependensi.
Menurut pendapat kami, metodologi untuk menerapkan analisis peringkat belum cukup dikembangkan. Secara khusus, penentuan parameter sistem peringkat dilakukan terutama dengan metode pendekatan kurva eksperimental menggunakan teknologi komputer. Metode rektifikasi, yang banyak digunakan oleh fisikawan penelitian, tidak digunakan dalam studi cenosis dengan metode analisis peringkat.
Kami telah melengkapi metode analisis peringkat dengan tahap meluruskan distribusi peringkat grafis H dalam koordinat logaritmik ganda (penambahan tahap 6 atau menyoroti tahap terpisah antara 6 dan 7). Garis singgung sudut kemiringan garis lurus ke sumbu absis menentukan parameter .
Mari kita pertimbangkan tahap ini secara lebih rinci untuk kasus umum - hiperbola yang dipindahkan ke atas sepanjang ordinat oleh B.
3. Perkiraan hiperbola dengan ketergantungan matematis dengan metode rektifikasi(Gbr. 1, a, b).
Penerapan metode rektifikasi pada hiperbola yang dipindahkan ke atas relatif terhadap sumbu ordinat (Gbr. 1, a) dijelaskan secara rinci dalam pekerjaan.
Sumbu W Y atau ln (W-B)
1 R ln r1 sumbu x
Beras. 1. Hiperbola (a) dan ketergantungan hiperbolik "diperbaiki" pada skala logaritmik ganda (b)
Mari kita periksa fungsi dari bentuk:
W = B + A / r , (2)
di mana B adalah konstanta: karena r cenderung tak terhingga, W = B.
Penelitian ini meliputi tahapan sebagai berikut.
1. Pindahkan konstanta B ke ruas kiri persamaan
W - B = A / r (2а)
2. Mari kita ketergantungan logaritma (2а):
Ln (W - B) = lnA - ln r (3)
3. Mari kita tentukan:
Ln (W - B) = pada; LnА = b = konstan; Ln r = x. (4)
4. Mari kita nyatakan fungsi (3) dengan memperhitungkan (4) dalam bentuk:
Y = b - x(5)
Persamaan (5) adalah fungsi linier dari bentuk Gambar 1, b. Hanya ordinatnya adalah Ln (W - B), dan absisnya adalah Ln r.
5. Mari kita menyusun tabel nilai eksperimen ln (W-B) dan ln r
Nama individu (memperingkat objek) | |||||||
6. Mari kita buat grafik ketergantungan eksperimental
ln (W– B) = f (ln r).
7. Mari kita menggambar garis lurus sedemikian rupa sehingga sebagian besar titik terletak pada garis lurus dan dekat dengannya (Gbr. 1, b).
8. Mari kita cari koefisien dengan garis singgung sudut kemiringan garis lurus ke sumbu absis dari grafik pada Gambar. 1b, menghitungnya menggunakan rumus:
= tan = (b - b1): ln r1 (6)
9. Hitung koefisien B menggunakan rumus (2). Dari (2) berikut bahwa:
Untuk r , W =
10. Cari nilai A dari grafik menggunakan persamaan (2a):
untuk r = 1, W - B = A, tetapi W = W1,
Karena itu:
Dimana W1 adalah nilai parameter W dengan rank r = 1.
11. Kolaborasi dengan distribusi tabulasi dan grafis secara bertahap:
Menemukan titik anomali sesuai jadwal;
Penentuan koordinat mereka dan identifikasi mereka dengan individu dengan distribusi yang ditabulasikan;
Analisis penyebab anomali dan pencarian cara untuk menghilangkannya.
Catatan
Jika B = 0, maka hiperbola dan ketergantungan yang dikoreksi memiliki bentuk (Gbr. 2, a, b):
W ln Whttps: //pandia.ru/text/80/082/images/image016_8.gif "height =" 135 ">
 SEBUAH
SEBUAH
Koefisien ditentukan dengan rumus:
= tan = lnA: ln r
Koefisien A ditentukan dari kondisi:
kesimpulan
Teknik yang dijelaskan dapat diterapkan untuk mempelajari berbagai cenosis: fisik, teknis, biologis, ekonomi, sosial, dll.
Tahap 7 dari pendekatan dan menemukan parameter distribusi analisis peringkat dilengkapi dengan metode "pelurusan", yang dapat digunakan sebagai metode alternatif untuk pendekatan komputer (bahkan secara manual).
Perbandingan eksperimental dari dua metode untuk menentukan parameter distribusi peringkat hiperbolik (perkiraan komputer langsung ke distribusi H eksperimental dan metode pelurusan hiperbola dalam skala logaritmik ganda juga menggunakan komputer) menunjukkan kecukupannya. Dalam hal ini, metode pelurusan memiliki keuntungan sebagai berikut. Pertama, memungkinkan parameter untuk ditentukan lebih akurat. Kedua, lebih bersifat visual: anomali berupa titik-titik yang keluar dari garis lurus tampak lebih jelas pada grafik yang diluruskan.
Bibliografi:
1. Kudrin bibliografi di bidang teknik dan teknik elektro. Dalam rangka HUT ke-70 kelahiran prof. / Disusun oleh:,. Edisi umum:. Edisi 26 "Studi Sensus". - M.: Pusat Penelitian Sistem, 2004. - 236 hal.
2. Kudrin dalam teknik. 2nd ed., Direvisi, tambahkan. –Tomsk: TSU, 1993. –552 hal.
3. Kudrin BV, Oshurkov penentuan parameter konsumsi listrik industri multi-domain, - Tula. Priok. buku penerbit, 1994. -161 hal.
4. Kudrin swaorganisasi. Untuk teknisi listrik dan filsuf // Edisi. 25. "Studi Sensus". - M.: Pusat Penelitian Sistem. - 2004 .-- 248 hal.
5. Deskripsi matematis cenosis dan hukum teknologi. Filsafat dan Formasi Teknik / Ed. // Studi cenologi. –Vis. 1-2. - Abakan: Pusat Penelitian Sistem. – 1996 .-- 452 detik.
6. Kudrin lagi tentang gambaran ilmiah ketiga dunia. Tomsk. Rumah penerbitan Tomsk. Universitas, 2001 –76 hal.
7., Perkiraan Kudrin dari distribusi peringkat dan identifikasi technocenosis // Edisi 11. “Studi Sensus”. - M.: Pusat Penelitian Sistem - 1999. - 80 hal.
8. Chirkov di dunia mesin // Masalah. 14. "Studi Sensus". - M.: Pusat Penelitian Sistem. - 1999.-272 hal.
9. Konstruksi Gnatyuk dari technocenosis. Teori dan Praktek // Masalah. 9. "Studi Sensus". - M.: Pusat Penelitian Sistem. - 1999 .-- 272 hal.
10. Gnatyuk konstruksi optimal technocenosis. / Monografi - Edisi 29. Studi Sensus. - Moskow: TSU Publishing House - Pusat Penelitian Sistem, –2005. - 452 hal. (versi komputer ISBN 5-7511-1942-8). -http: //www. baltnet. ru / ~ gnatukvi / ind. html.
11.Analisis Gnatyuk tentang technocenosis // Listrik – 2000. 8. –S.14-22.
12., V. Belov, penilaian konsumsi daya sejumlah lembaga pendidikan // Listrik. - Nomor 5. - 2001. - S.30-35.
14. Analisis gurin sistem pendidikan (pendekatan cenologis). Rekomendasi metodis untuk pendidik Edisi 32. “Studi Sensus”. –M.: Teknik. - 2006 .-- 40 hal.
15. Penelitian Gurina tentang sistem pendidikan pedagogis // Polzunovskiy Vestnik. –2004. -Nomor 3. - S.133-138.
16. Analisis Gurin atau pendekatan sensus dalam pendidikan // Teknologi sekolah. - 2007. - No. 5. - S.160-166.
17. Gurina, - penelitian eksperimen fisika dengan pengolahan komputer hasil: praktikum laboratorium. Rekomendasi metodis untuk guru fisika kelas fisik dan matematika khusus. - Ulyanovsk: UlSU, 2007 .-- 48 hal.
1 Menurut metodologi, pengukuran dan persebaran jenis bencana alam dilakukan berdasarkan data kerusakan, jumlah korban dan kematian menurut jenis bencana alam. Kemudian, langkah-langkah dirancang untuk mencegah kemungkinan bencana alam di masa depan. Diketahui bahwa ramalan ilmiah dan peringatan tepat waktu dapat mengurangi kerusakan lingkungan dari kemungkinan bencana alam.Sebelum merancang tindakan, diusulkan untuk menentukan dengan memodelkan pola distribusi dalam urutan jumlah bencana. Untuk ini, nilai setiap indikator diberi peringkat bilangan bulat, mulai dari nol. Selanjutnya, sesuai dengan nilai indikator dengan peringkat bilangan bulat, keteraturan distribusi peringkatnya diperoleh.
Distribusi dalam urutan jumlah bencana nilai kerusakan, jumlah korban dan korban ditentukan oleh rumus umum untuk banyak proses
di mana Y adalah indikator; r adalah peringkat bilangan bulat yang diambil dari seri 0, 1, 2, 3, ...; a 1 ... a 7 adalah parameter model statistik, yang menerima nilai numerik untuk distribusi kerusakan tertentu, jumlah korban luka dan tewas.
Di mana aktivitas pengaruh natural-natural 1 dan technogenic 2 interferensi dalam distribusi nilai indikator Y = Y 1 + Y 2 dihitung dengan rumus α 1 = Y 1 / Y dan 2 = Y 2 / Y. Kemampuan beradaptasi seseorang k dengan intervensi teknogeniknya, termasuk tindakan untuk mencegah bencana alam, ditentukan oleh rasio komponen teknogenik dari pola umum dengan komponen kedua, yaitu, dengan ekspresi matematika k = Y 2 / Y 1 .
Contoh dari... Menurut data identifikasi (1), diperoleh keteraturan.
1. Jumlah berbagai jenis bencana alam yang pernah terjadi di dunia selama 30 tahun (1962-1992) berubah dari segi kerusakan material (Tabel 1) menurut polanya
Tabel 1. Jumlah bencana di dunia selama 30 tahun (1962-1992) dengan kerusakan harta benda
|
bencana |
Nilai yang dihitung (2) |
||||
Meja 1 dan lainnya, jenis bencana berikut diadopsi: GL - kelaparan; - embun beku; - kekeringan; - gempa bumi; IW - letusan; ND - banjir; - invasi serangga; OP - tanah longsor; PZh - kebakaran; TL - longsoran salju; CX - angin kering; TSh - badai tropis; TsN - tsunami; SHT - badai; ED - epidemi.
Komponen pertama (2) menunjukkan proses alami dari distribusi peringkat jenis bencana alam, dan yang kedua - kegembiraan manusia yang penuh tekanan untuk kerusakan material, sebagai respons negatif ("+") terhadap tindakan yang tidak memadai untuk mencegah situasi darurat dan menghilangkan konsekuensi dari bencana masa lalu.
Indikator kecukupan model (2) dan lainnya ditentukan sebagai berikut. Perbedaan antara nilai aktual dan nilai yang dihitung dari indikator digunakan untuk menghitung kesalahan absolut dengan ekspresi. Kesalahan relatif (%) ditentukan dari ekspresi. Dari residu ini, nilai maksimum max (modulo) dipilih, yang dalam tabel. 1 digarisbawahi. Maka probabilitas kepercayaan D dari keteraturan statistik yang ditemukan akan sama dengan ![]() ... Dari tabel datanya. 1 bahwa kesalahan relatif maksimum dari rumus (1) adalah 52,0%. Pada saat yang sama, diketahui bahwa distribusi dalam urutan menurun dari nilai indikator memiliki kesalahan yang signifikan di akhir seri. Oleh karena itu, nilai terakhir dari seri dapat diabaikan; pada peringkat 7, 8 dan 9, jumlah bencana sama dengan satu. Mereka adalah 3 x 100/241 = 1,24%. Jika kami mengecualikannya, maka kesalahan maksimum rumus (2) adalah 20,75%. Keyakinan pada (2) akan menjadi setidaknya 100 - 20,75 = 79,25%. Kepercayaan tersebut akan memungkinkan penerapan rumus (2) dalam perhitungan perkiraan kerusakan material dari bencana di masa depan yang diharapkan di masa depan.
... Dari tabel datanya. 1 bahwa kesalahan relatif maksimum dari rumus (1) adalah 52,0%. Pada saat yang sama, diketahui bahwa distribusi dalam urutan menurun dari nilai indikator memiliki kesalahan yang signifikan di akhir seri. Oleh karena itu, nilai terakhir dari seri dapat diabaikan; pada peringkat 7, 8 dan 9, jumlah bencana sama dengan satu. Mereka adalah 3 x 100/241 = 1,24%. Jika kami mengecualikannya, maka kesalahan maksimum rumus (2) adalah 20,75%. Keyakinan pada (2) akan menjadi setidaknya 100 - 20,75 = 79,25%. Kepercayaan tersebut akan memungkinkan penerapan rumus (2) dalam perhitungan perkiraan kerusakan material dari bencana di masa depan yang diharapkan di masa depan.
Meja 2. Analisis Model Statistik (2)
Meja 2 menunjukkan hasil penghitungan komponen N 1 dan N 2 dari rumus (2), serta nilainya faktor signifikansi 1 dan 2 dari komponen ini kerusakan material dan koefisien adaptasi k kemanusiaan (pada saat pencatatan dinamika jumlah bencana) hingga distribusi jumlah bencana.
Dari tabel datanya. 2, dapat dilihat bahwa pada peringkat 6-9 koefisien adaptasi manusia terhadap letusan, tanah longsor, tsunami dan salju dalam hal kerusakan material cenderung tak terhingga.
Seseorang belum dapat mengatasi kebakaran pada k = 15.00.
2. Jumlah jenis bencana alam di dunia selama 30 tahun (1962-1992), dibedakan berdasarkan jumlah korban, berubah menurut keteraturan statistik (tab. 3, tab. 4)
Dari meja. 4 menunjukkan bahwa rangsangan stres maksimal untuk rasa lapar (peringkat 4).
3. Jumlah jenis bencana alam di dunia menurut jumlah korban jiwa mendapat pola (Tabel 5 dan Tabel 6) menurut rumus
|
Tabel 3. Jumlah bencana di dunia dalam 30 tahun (1962-1992) dengan jumlah korban
|
Tabel 4. Analisis Model Statistik (3) |
|||||||||||||||
|
Tabel 5. Jumlah bencana di dunia dalam 30 tahun (1962-1992) dengan jumlah kematian
|
Tabel 6. Analisis model (6) jumlah bencana |
|||||||||||||||
Dari tabel datanya. 6 dapat dilihat bahwa kegembiraan manusia yang penuh tekanan adalah maksimum untuk badai, yang memiliki peringkat kelima dalam hal jumlah kematian.
Untuk membuktikan bahwa model tipe (1) adalah hukum yang stabil, perlu bahwa koefisien yang diadopsi dari aktivitas dan kemampuan beradaptasi juga berubah sesuai dengan hukum yang stabil.
Menurut tabel. Didapatkan 6 model untuk data jumlah korban tewas:
koefisien signifikansi komponen pertama model (4) adalah
koefisien signifikansi komponen kedua;
koefisien adaptasi manusia terhadap bencana alam dalam hal jumlah kematian selama 30 tahun (1962-1992) berubah menurut rumus
Menurut tiga indikator, dan mungkin ada banyak dari mereka, adalah mungkin untuk menentukan tempat peringkat m r (dalam contoh ini, tanpa memperhitungkan koefisien bobot indikator) dari setiap jenis bencana alam (dan di masa depan, bukan alam) (Tabel 7).
|
Jenis bencana alam |
Kerusakan material |
Jumlah korban |
Korban tewas |
|||||||
|
GL - lapar |
||||||||||
|
- embun beku |
||||||||||
|
- kekeringan |
||||||||||
|
- gempa bumi |
||||||||||
|
IW - letusan |
||||||||||
|
ND - banjir |
||||||||||
|
- invasi serangga |
||||||||||
|
OP - tanah longsor |
||||||||||
|
PZh - kebakaran |
||||||||||
|
SL - longsoran salju |
||||||||||
|
CX - angin kering |
||||||||||
|
TSh - badai tropis |
||||||||||
|
TsN - tsunami |
||||||||||
|
PCS - badai |
||||||||||
|
ED - epidemi |
||||||||||
Catatan: banjir paling berbahaya, dan salju aman.
Penggunaan metode analisis peringkat dalam persebaran bencana alam menurut jenisnya akan memperluas klasifikasi bencana, khususnya dengan memasukkan jenis bencana alam baru, dan di masa depan, kelas-kelas dari semua jenis dampak antropogenik.
BIBLIOGRAFI:
- Korobkin, V.I. Ekologi: buku teks untuk universitas / V.I. Korobkin, L.V. Peredelskiy. - Rostov di Don: Rumah penerbitan "Phoenix", 2001. - 576 hal.
- Mazurkin, P.M. Ekologi statistik / P.M. Mazurkin: Buku teks. - Yoshkar-Ola: MarSTU, 2004 .-- 308 hal.
- Mazurkin, P.M. Geoekologi: Keteraturan ilmu alam modern: Scientific ed. / PM. Mazurkin. - Yoshkar-Ola: MarSTU, 2006 .-- 336 hal.
- Mazurkin, P.M. Pemodelan statistik. Pendekatan heuristik-matematis / P.M. Mazurkin. - Publikasi ilmiah. - Yoshkar-Ola: MarSTU, 2001 .-- 100 hal.
- Mazurkin, P.M. Pemodelan matematika. Identifikasi pola statistik satu faktor: Textbook / P.M. Mazurkin, A.S. Filonov. - Yoshkar-Ola: MarSTU, 2006 .-- 292 hal.
Referensi bibliografi
Mazurkin P.M., Mikhailova S.I. JANGKAUAN DISTRIBUSI JENIS BENCANA ALAM // Teknologi modern sains-intensif. - 2008. - No. 9. - S. 50-53;URL: http://top-technologies.ru/ru/article/view?id=24197 (tanggal diakses: 26/12/2019). Kami menyampaikan kepada Anda jurnal-jurnal yang diterbitkan oleh "Academy of Natural Sciences"